AI can be scary for white-collar office workers — like myself — who wanted to stay professionally active for a few more years. It writes computer programs in languages I’ve never heard of. It makes presentations, phrases letters, writes blog posts, drafts diagrams, analyzes data. But it’s not just scary — it’s exciting and interesting too. So let’s set aside our existential crisis for a moment and appreciate what’s now possible. This post draws an
It will be uncomfortable to read back in 2027, once it becomes clear how many things I missed and how many predictions I got wrong. Still, I hope you’ll enjoy reading this
Here’s what I’ll cover: why AI is becoming an integration platform rather than a replacement tool, why smaller models are improving faster than frontier ones, how verifiable AI could make “vibe coding” enterprise-ready, and why the 95% enterprise AI failure rate is about to drop significantly. Along the way, some thoughts on security, knowledge graphs, the TSMC bottleneck, and whether you should learn to bake and brew coffee as a plan B.
AI as Integration Platform: 2026 Is the Year of Collaboration
It’s impressive that AI can write code and solve mathematical theorems. But
Enterprises have well-tested, reliable workflows that took years to build.
This realization is shifting how companies think about their AI roadmaps.
Now, consider what a single complex task looks like in practice. Analyzing a market entry opportunity might need a data retrieval agent, a financial modeling agent, a regulatory compliance agent, and a report generator.
On the supplier side, you can already find third-party agents on Google Cloud Platform and AWS Marketplace. However, these don’t yet solve your problem end-to-end — they can’t automatically select the right agents based on your budget and predicted token usage for a given task. But they will. And if you’re an SME without an internal platform and years of accumulated data, you’ll rely on these external providers. Within these platforms, there will be competition among agents: only well-tested ones will be able to command premium prices, while new providers will need to offer lower rates until their track record grows. The platform will split the payment and take a commission. Some blockchain-based B2B agent platforms already exist, but none has emerged as the standard yet — and most are still far from production quality.
Meanwhile, the
For building usable AI platforms, several building blocks need to mature: efficient on-premise models (you can’t share all your data with third-party vendors), verifiable AI (you need to know the problem is actually solved), secure AI (always), and efficient search across an ocean of data and tools. Plus humans — to drive the innovation that can’t be taught yet. And silicon — because everything runs on chips. The next sections cover these pieces.
(A technical note: these collaborative agent platforms likely won’t follow a hierarchical “CEO agent delegates to mid-level managers” pattern. More democratic algorithms — where agents bid on tasks based on their capabilities and pricing — tend to be more effective. Think auction-based orchestration rather than top-down command.)
Local Intelligence and Efficient Small Models
The
The next paragraph gets technical. Feel free to skip — a dedicated (and more accessible) post on inference engine internals is coming.
There’s a floor to how little computation you need for solving complex tasks. A 7B to 70B active parameter range seems necessary for complex reasoning. But within that range, you can save significant resources, driven by two forces:
- First, inference engines are getting much smarter. Tools like vLLM — the serving infrastructure between your application and the model — are solving the practical hardware utilization challenges that arise in real deployments. A GPU’s processing capacity is only as useful as its memory bandwidth allows. With concurrent users sending requests of wildly different lengths, keeping both optimally busy requires smart scheduling. Continuous batching slots new requests the moment a slot frees, rather than waiting for a whole batch to finish. Memory is equally constrained: modern large models use a Mixture-of-Experts architecture, where only a subset of specialized “expert” sub-networks activates per token. Inference engines exploit this by keeping frequently used experts resident in GPU memory while offloading the rest — effectively running a model far larger than the GPU’s VRAM would otherwise allow. These optimizations are still maturing, with better CPU-GPU hybrid execution and smarter memory hierarchies on the roadmap.
- Second, model architectures are evolving beyond pure Transformers. Hybrid State Space Models like NVIDIA’s Nemotron-3 Nano — a Mamba-Transformer hybrid — offer massive context windows with significantly faster and cheaper inference than traditional Transformers. Instead of processing every token against every other token (the quadratic cost that makes long contexts expensive), these hybrids selectively use attention only where it matters.
Local models will also handle multi-modal inputs more fluidly — processing text, images, and structured data together rather than as separate pipelines — which is necessary for wider adoption.
Verifiable and Explainable AI
AI-assisted coding does make development significantly faster for routine, well-structured tasks. The general speedup varies — studies report 30–55% for scoped tasks, though for highly structured work like writing ETL pipelines or containerizing deployments (where coding standards and templates are well-documented), the gains can reach 2–3x.
This is where verifiable AI enters the picture.
From the user’s perspective, verifiability matters just as much for analytics and dashboards. When an automated tool calculates a result or adds a new KPI to a dashboard, you need to understand how it got there. The queries and logic should be explainable alongside the results.
Secure AI
As AI agents gain more autonomy and access to sensitive systems, security becomes non-negotiable. The vulnerabilities are real: the same prompt injection techniques that make for entertaining LinkedIn posts about “lousy AI providers” are the exact mechanics behind real security breaches - stealing data, executing unauthorized code, or hijacking entire applications. I covered the attack surface and defense strategies in detail in a previous post.
The core principle hasn’t changed: defense requires layers. It starts with architecture - restricting the LLM to calling controlled functions rather than writing arbitrary code, limiting API access to the user’s own permissions, and sandboxing execution so that even when something goes wrong, the blast radius stays contained.
On top of architecture,
Large RAG and Graph AI
Now consider the data landscape.
Much of this data is contradictory. Some is outdated. Some comes from unreliable sources. Some tools work well; others don’t. And your complex task probably needs several of them together, pulling fragments from across this entire ocean.
This means
On top of complexity, there’s speed. Your retrieval system needs to be fast, not just thorough. At Lynx Analytics, we use Graph AI to address these challenges — representing knowledge as connected graphs rather than flat document collections, which lets agents traverse relationships and find non-obvious connections between pieces of information.
The Human Touch - Reducing Failures
A widely cited
People working on AI transformation have gotten more humble and patient. They’ve learned what AI can and can’t do, and they’ve stopped expecting magic — instead, they’re
Bottleneck: We Only Have One TSMC
The
- NVIDIA manufactures its GPUs at TSMC in Taiwan,
- Google produces its TPUs at TSMC in Taiwan,
- AMD produces its GPUs and CPUs at TSMC in Taiwan.
There are alternatives — Intel Foundry Services, Samsung, and SMIC (Huawei’s manufacturing partner) — but the most advanced process nodes are all at TSMC.
This is a concentration risk by any definition. And since
Some Peripheral Trends
Before we get to the “will I lose my job” section, here are a few more predictions and directions for the next year:
- Robotics and AR will produce impressive demos. Not just humanoid robots walking around, but task-specific machines doing useful things in warehouses, hospitals, and farms.
- IoT intelligence — smart devices communicating autonomously. Your smart scale advising your fridge on what to stock, so you can never eat a chocolate pudding at 11 PM again. (Whether this is a feature or a bug is left to the reader.)
- Specialized AI chips will appear in more consumer devices — though I’m not sure whether the fuzzy PID controller in my rice cooker will finally get an upgrade.
- AI regulation is moving. The EU AI Act is now in phased implementation, following the same trajectory as GDPR a decade ago. Other countries will follow with similar frameworks. This sounds like bureaucratic overhead, but clearer rules will actually accelerate enterprise adoption by reducing legal uncertainty.
- Quantum computing gets an interesting angle from verifiable AI: translating business problems into quantum-compatible formulations is one of the hard parts, and AI can help with that bridge. New theoretical work on quantum transformers and quantum attention mechanisms is emerging. But practical implementation remains years away — past 2030 for most use cases.
- Large consulting firms face an interesting challenge: the language barrier between management and technical teams can now be bridged with a $20/month AI subscription. An oversimplification, sure, but the threat is real. Routine advisory work will move in-house.
Riding the Waves
A former boss of mine used to say:
Always train your successor — that’s the only way you get new responsibilities.
The same principle applies, but your successor is now AI. So
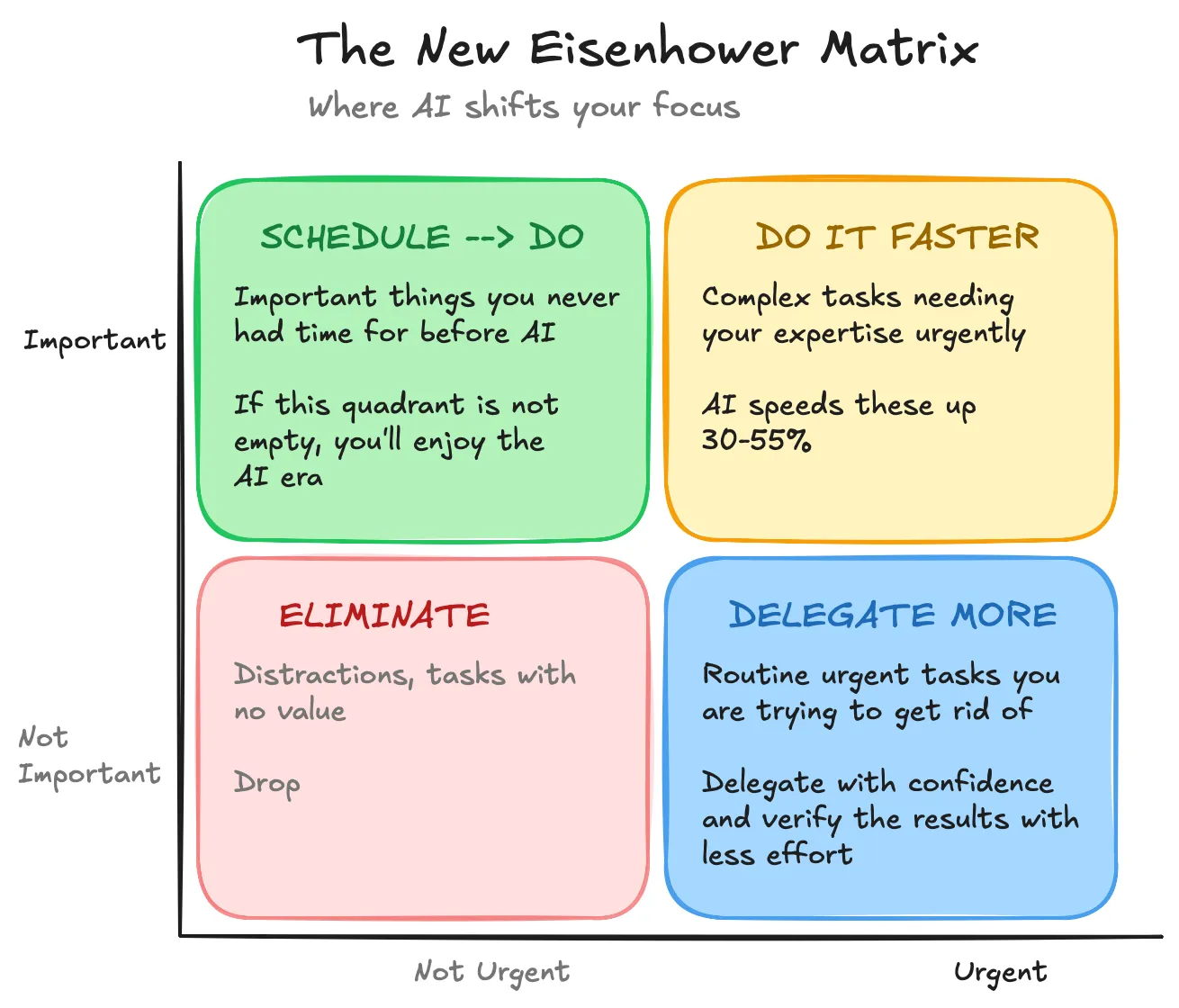
Figure 1: How AI shifts your focus
What are your predictions for 2026? I’d love to hear where you agree or disagree — comment on the LinkedIn post or drop a comment below. And do not forget to